GeekPlux's Wiki
Table of Contents
- 1. Programming
- 2. Web
- 3. Node
- 4. Android
- 5. Git
- 6. Text Editor
- 7. Org Mode
- 8. Chrome
- 9. OS
- 10. Database
- 11. Algorithm
- 12. Design
- 13. Research
- 14. Visualization
- 15. Machine Learning
- 16. Computer Graphics
- 17. Complex Network
- 18. Latex
- 19. 日本语学习
- 20. Life
- 21. Reading
This document, my personal wiki which shares my skills mastered and knowledges learned, is built by org-mode with the ReadTheOrg theme. I used to organize my knowledges by Evernote or other mind management APP, until I met Spacemacs and discovered the Org mode, life became more wonderful.
1 Programming
-
看看这篇文章的发布日期,再对比现在的技术潮流,就知道这篇文章还没有过时,所以按照这篇文章修炼是不会错的。技术越学到最后越偏底层。
1.1 Mooc courses
1.1.1 Computer Science
1.1.2 Programming Languages - University of Washington
1.2 命令式(imperative)与函数式(functional)语言
- 程序设计的主流是命令式程序设计,计算基于一组基本操作,在一个环境里进行。操作效果是改变环境的状态,体现在所创建和修改的状态中。
- 函数式程序设计中计算过程被看成是数据的变换,程序的行为就是对数据的一系列变换。
1.3 SICP notes
1.4 Language
1.4.1 Lisp
1.4.2 Python
- Python Basic
- OS, System, File
使用 glob 模块可以用通配符的方式搜索某个目录下的特定文件,返回结果是一个 list
import glob flist=glob.glob('*.jpeg')
使用 os.getcwd()可以得到当前目录,如果想切换到其他目录,可以使用 os.chdir('str/to/path'),如果想执行 Shell 脚本,可以使用 os.system('mkdir newfolder')。
对于日常文件和目录的管理, shutil 模块提供了更便捷、更高层次的接口
import shutil shutil.copyfile('data.db', 'archive.db') shutil.move('/build/executables', 'installdir')
如果要在代码中添加中文注释的话,最好在文档开头加上下面的编码声明语句。关于 Python 中的字符串编码可见廖雪峰的 python 教程。若代码打算用在国际化的环境中, 那么不要使用奇特的编码。Python 默认的 UTF-8, 或者甚至是简单的 ASCII 在任何情况下工作得最好。同样地,如果代码的读者或维护者只有很小的概率使用不同的语言,那么不要在标识符里使用非 ASCII 字符。
# coding=utf-8 或者 # -*- coding: utf-8 -*-
- List
>>> a = [0,[1,2]] >>> b = a >>> b[0] = 88 >>> b[1][0] = 99 >>> b [88, [99, 2]] >>> a [88, [99, 2]] >>> # 并未真正生成一个新的列表,b 指向的仍然是 a 所指向的对象。这样,如果对 a 或 b 的元素进行修改,a,b 的值同时发生变化。 >>> # 好吧,用[:]试试看 >>> a = [0,[1,2]] >>> b = a[:] >>> b[0] = 88 >>> b[1][0]=99 >>> b [88, [99, 2]] >>> a [0, [99, 2]] >>> # 这种方法只适用于简单列表,也就是列表中的元素都是基本类型,如果列表元素还存在列表的话,这种方法就不适用了,原因就是,像 a[:]这种处理,只是将列表元素的值生成一个新的列表,如果列表元素也是一个列表,如:a = [0,[1,2]],那么这种复制 对于元素[]的处理只是复制[1,2]的引用,而并未生成 [1,2]的一个新的列表复制。
- OS, System, File
- Cheat Sheet
- Naming Styles
# see: PEP8 # for public use var # for internal use _var # convention to avoid conflict keyword var_ # for private use in class __var # for protect use in class _var_ # "magic" method or attributes # ex: __init__, __file__, __main__ __var__ # for "internal" use throwaway variable # usually used in loop # ex: [_ for _ in range(10)] # or variable not used # for _, a in [(1,2),(3,4)]: print a _
- for: exp else: exp
# see document: More Control Flow Tools # forloop’s else clause runs when no break occurs >>> for _ in range(5): ... print _, ... else: ... print "\nno break occur" ... 0 1 2 3 4 no break occur >>> for _ in range(5): ... if _ % 2 ==0: ... print "break occur" ... break ... else: ... print "else not occur" ... break occur # above statement equivalent to flag = False for _ in range(5): if _ % 2 == 0: flag = True print "break occur" break if flag == False: print "else not occur"
- Check object attributes
# example of check list attributes >>> dir(list) ['__add__', '__class__', ...]
- Define a function doc
# Define a function document >>> def Example(): ... """ This is an example function """ ... print "Example function" ... >>> Example.__doc__ ' This is an example function ' # Or using help function >>> help(Example)
- Check all global variables
# globals() return a dictionary # {'variable name': variable value} >>> globals() {'args': (1, 2, 3, 4, 5), ...}
- Naming Styles
- Python 的两大应用方向
Python 我个人觉得有两大方向,一是 Web 方面,一是科研方面。 Web 方面有 Flask, Django 等成熟的框架。科研方面有很多完备的科学计算库和绘图工具:
A Guide to Python's Magic Methods « rafekettler.com
- Numpy 学习资源:
Matplotlib 学习资源:Matplotlib tutorial
python 在大数据方面的武器列表:

1.4.3 Ruby
Ruby 是解释执行的,且每条 Ruby 代码都会返回某个值。 Ruby 是一门纯面向对象语言。在 Ruby 中,一切皆为对象。
- tips
- 除了 nil 和 false 之外,其他值都代表 true
- 每个函数都会返回结果。如果你没有显式指定某个返回值,函数就将返回退出函数前最后处理的表达式的值。
- links
- 导入 CSV 文件
刚开始用了 ruby 自带的 CSV 库,后来用了 tilo/smartercsv: Ruby Gem for smarter importing of CSV Files as Array(s) of Hashes, with optional features for processing large files in parallel, embedded comments, unusual field- and record-separators, flexible mapping of CSV-headers to Hash-keys 然而还是特别慢(可能因为我数据量巨大,一个 CSV 文件大概 1G),不过后者比前者的速度确实快了不少。另外 ruby-china 有个帖子对导入大文件有过分析,挺不错的:使用 Ruby 处理大型 CSV 文件 · Ruby China
1.4.4 Shell
- Shell 编程
Shell 脚本是解释型的,而不是编译型的。符号`#!`用来告诉系统这个脚本用什么程序执行
#!/bin/sh
- 变量
- 定义变量时,变量名不加美元符号($)
- 使用一个已定义的变量,只需在变量名前面加美元符号即可
- 变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界
- 用
local可将函数内的变量定义为局部变量 用
declare声明变量可以限定其使用范围,常用的两个:-a 变量为数组。 -r 使得变量变为只读。这些变量不能被后来的赋值与语句赋值,同样也不可以 unset。
readonly可以定义常量,感觉和 declare -r 差不多
- 流程控制
- 条件
if ...; then ... elif ...; then ... else ... fi
if 中常用的测试表达式:
- [ -d FILE ] 如果 FILE 存在且是一个目录则为真。
- [ -e FILE ] 如果 FILE 存在则为真。
- [ -f FILE ] 如果 FILE 存在且是一个普通文件则为真。
- [ -h FILE ] 如果 FILE 存在且是一个符号连接则为真。
- [ -p FILE ] 如果 FILE 存在且是一个名字管道(F 如果 O)则为真。
- [ -r FILE ] 如果 FILE 存在且是可读的则为真。
- [ -s FILE ] 如果 FILE 存在且大小不为 0 则为真。
- [ -w FILE ] 如果 FILE 如果 FILE 存在且是可写的则为真。
- [ -x FILE ] 如果 FILE 存在且是可执行的则为真。
- [ -O FILE ] 如果 FILE 存在且属有效用户 ID 则为真。
- [ -G FILE ] 如果 FILE 存在且属有效用户组则为真。
- [ -L FILE ] 如果 FILE 存在且是一个符号连接则为真。
- [ -S FILE ] 如果 FILE 存在且是一个套接字则为真。
- [ -z STRING ] “STRING” 的长度为零则为真。
- [ -n STRING ] “STRING” 的长度为非零则为真。
- 循环
for .. in ...; do ... done for while ...; do ... done 还有: until select shift break 语句用来在正常结束之前退出当前循环 continue 语句继续 for, while, until or select 内的循环
- 条件
- 参数
- 位置参数
$1, $2,..., $N来作参数 $#代表了命令行的参数数量$0当前脚本文件名$?上一个命令的退出码$$当前 Shell 进程 ID$@所有参数的列表$*和$@相同都是所有参数,但"$*" 和 "$@"(加引号)并不同,"$*"将所有的参数解释成一个字符串,而"$@"是一个参数数组
- 位置参数
- I/O
echo 输出 read 读取用户输入 管道 `|` 将一个命令的输出作为另外一个命令的输入 重定向:将命令的结果输出到文件,而不是标准输出(屏幕)
- tips
获取当前脚本运行的目录:
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )" # 具体含义 ${BASH_SOURCE[0]} 取得执行 shell 命令例如 tmp/test.sh dirname 取得前面的路径 cd 进到目录里 && pwd 打印当前路径
获取当前系统名:
OS="$(get_os)"
判断命令是否存在:
cmd_exists() { command -v "$1" &> /dev/null return $? }
- 变量
- Resources
1.4.5 PHP
1.4.6 C++
1.4.7 Make
1.4.8 Haskell
1.4.9 Go
1.6 Regex
2 Web
2.1 HTML&CSS
- 编码规范 by @mdo - 编写灵活、稳定、高质量的 HTML 和 CSS 代码的规范
- CSS Guidelines - High-level advice and guidelines for writing sane, manageable, scalable CSS
- 网易前端规范 - 真心不错
2.1.1 <Script>
如果<script>包含了 src 属性,那它中间再包含代码是不会执行的默认<script>在 HTML 中是按标签先后顺序加载的。除非有 defer 和 async 属性。
- defer 脚本会延迟到页面解析完毕后再运行(只适用于外部文件,在现实中,延迟脚本不一定按照顺序执行,也不一定会在 DOMContentLoaded 事件触发前执行)
- async 异步脚本同样不一定按照顺序执行。一定会在页面 load 事件前执行。
2.1.2 <noscript>
浏览器不支持脚本或脚本被禁用时显示该标签内的内容
2.1.3 Doctype
最初的文档模式有两种:混杂模式和标准模式不声明 doctype 会导致浏览器会开启混杂模式
2.1.4 Meta tag
<meta> 提供关于 HTML 文档的元数据。元数据不会显示在页面上,但对于浏览器、搜索引擎和其他 Web 服务都非常有用。
申明编码 <meta charset='utf-8' /> 优先使用 IE 最新版本和 Chrome <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" /> <!-- 关于 X-UA-Compatible --> <meta http-equiv="X-UA-Compatible" content="IE=6" ><!-- 使用 IE6 --> <meta http-equiv="X-UA-Compatible" content="IE=7" ><!-- 使用 IE7 --> <meta http-equiv="X-UA-Compatible" content="IE=8" ><!-- 使用 IE8 -->
有两个主要的属性可定义:
- name
可自定义属性名,如:
<meta name="keywords" content="HTML,META">常见的
name:- keywords 关键词,方便人们和 SEO
- description
- author
- robots 搜索引擎的索引方式
- viewport
viewport 应用于响应式网站的开发
<meta name="viewport" content="width=device-width, initial-scale=1.0,maximum-scale=1.0, user-scalable=no"/>
- width:宽度(数值 / device-width)(范围从 200 到 10,000,默认为 980 像素)
- height:高度(数值 / device-height)(范围从 223 到 10,000)
- initial-scale:初始的缩放比例 (范围从>0 到 10)
- minimum-scale:允许用户缩放到的最小比例
- maximum-scale:允许用户缩放到的最大比例
- user-scalable:用户是否可以手动缩 (no,yes)
minimal-ui:可以在页面加载时最小化上下状态栏。(已弃用)
注意,很多人使用 initial-scale=1 到非响应式网站上,这会让网站以 100%宽度渲染,用户需要手动移动页面或者缩放。如果和 initial-scale=1 同时使用 user-scalable=no 或 maximum-scale=1,则用户将不能放大/缩小网页来看到全部的内容。
- http-equiv
服务器在收发文档时的属性/值
虽然有些服务器会发送许多这种名称/值对,但是所有服务器都至少要发送一个:content-type:text/html。这将告诉浏览器准备接受一个 HTML 文档。
使用带有 http-equiv 属性的 <meta> 标签时,服务器将把名称/值对添加到发送给浏览器的内容头部。例如,添加:
<meta http-equiv="charset" content="iso-8859-1"> <meta http-equiv="expires" content="31 Dec 2008">
这样发送到浏览器的头部就应该包含:
content-type: text/html charset:iso-8859-1 expires:31 Dec 2008
当然,只有浏览器可以接受这些附加的头部字段,并能以适当的方式使用它们时,这些字段才有意义。
2.1.5 技巧:
2.1.6 学习 CSS:
2.1.7 手册:
2.1.8 Flexbox
Flexbox 布局比较适合 Web 应用程序的一些小组件和小规模的布局,而 Grid 布局更适合用于一些大规模的布局。常规布局是基于文本流和盒模型,而 Flex 是基于“Flex-flow”的:

- Container 重要属性
- flex-direction: row | row-reverse | column | column-reverse; 指定 flex-flow 方向 - flex-wrap: nowrap | wrap | wrap-reverse; 是否换行 - justify-content: flex-start | flex-end | center | space-between | space-around; 指定沿着主轴对齐方式 - align-items: flex-start | flex-end | center | baseline | stretch; 指定沿侧轴对齐方式
- Items 重要属性
- flex-grow: <number>; /* default 0 */ Item 扩大比例 - flex-shrink: <number>; /* default 1 */ Item 缩小比例 - flex-basis: <length> | auto; /* default auto */ Item 在 Container 剩余空间之前的一个默认尺寸 - align-self: auto | flex-start | flex-end | center | baseline | stretch; 覆盖默认的对齐方式
flex是flex-grow=,=flex-shrink和flex-basis三个属性的缩写
2.1.9 some tips
- 切图
- z-index
z-index 只在设置了 postion(即不是 static)的元素上起作用。具体可参考CSS z-index 属性的使用方法和层级树的概念 - NeoEase
2.2 JavaScript
当年我是通过《Javascript DOM 编程艺术》入门的,非常基础,循序渐进,一天就能看完
2.2.1 ECMAScript
- Number 类型:parseInt() 最好写上第二个参数
- String 类型:
- 转义序列表示一个字符
- ECMAScript 中字符串是不可变的。要改变字符串,首先得销毁原来的字符串,然后再创建一个包含新值的字符串来替换。(如字符串拼接)
null和undefined没有 toString() 方法
&和|操作属于短路操作,即如果第一个操作数能决定结果,那么就不会对第二个操作数求值
2.2.2 JSON
2.2.3 ES2015
2.2.4 Tips
tips 其实就是懒得整理的,遇到的各种坑。。。
- 创建二维数组
let arr = new Array(10).fill(new Array(10)); 此方法会导致每个子元素的数组都指向同一份数组的引用。
- Promise race
当 iterable 参数里的任意一个子 promise 被成功或失败后,父 promise 马上也会用子 promise 的成功返回值或失败详情作为参数调用父 promise 绑定的相应句柄,并返回该 promise 对象。
- 判断是否 NaN
isNaN() 只能判断 numbers
= 也是只能判断 numbers >能判断各种类型var a = NaN; a == a; // false var a = new Number(NaN); a == a; // true var a = new Number(NaN); a >= a; // false
2.3 CoffeeScript
CoffeeScript 作为一个可编译为 JS 的语言,在 ES2015 发布的时候就完成了它的历史使命。虽然我推荐在项目中直接用 ES2015,不过多了解一下 CoffeeScript 还是不错的。
2.4 Angular
如果用了 Angular,那么你的代码和项目规划就必须「Angular 化」。
要尽可能的符合 Angular 的实践方案,表面上 AMD 规范非常好用,其实存在很多弊端。比如你用一个不符合 AMD 规范的库,得先封装成一个 Angular Module Data-Binding 同样是有利有弊,不过这个还算可以避免。但 Angular 总是有些小坑。。(不是黑)
2.4.1 ui-router
Angular 本身的 Router 还好,但是 ui-router 用 state 方式来管理路由更加方便
ui-router 的 url 设计,最好和后台 API 接口统一。如果是 RESTful 的接口,则更加直观和方便。
2.4.2 Controller 之间通信
- 不习惯用 RootScope,把要变的东西绑在全局变量上总不是什么好事
- 习惯用事件来传递数据。=$emit, $broadcast, $watch=
- 特殊情况用 Service
2.5 Backbone
和 CoffeeScript 是同一个作者,代码总共 1000 多行,非常简洁优美。典型的 MVC 框架,其实通过 Backbone 就可以实现 Web Components。
collecction 和 model 非常好用。但由于过于轻量,很多东西需要自己来写,不过对于喜欢自己动手或喜欢「按需」搭配所需要功能的同学非常方便。
2.6 Vue
半小时入门,可以做出实际应用。结合了 Angular 和 React 两者的优点,写起来非常漂亮。语法和 Angular 差不多。
2.6.1 tips
自定义组件可以像普通元素一样直接使用 `v-for`:
<my-component v-for="item in items"></my-component> 但是,不能传递数据给组件,因为组件的作用域是孤立的。为了传递数据给组件,应当使用 props: <my-component v-for="item in items" :item="item" :index="$index"> </my-component> 不自动把 item 注入组件的原因是这会导致组件跟当前 v-for 紧密耦合。显式声明数据来自哪里可以让组件复用在其它地方。
2.6.2 vue-loader
webpack 组件,可 load `.vue` 文件 vuejs/vue-loader
2.6.3 vue-router
2.6.4 vue-resource
2.7 React
关于 React 中使用 ES6 遇到的若干问题:Reusable Components | React
关于 React-router 使用 ES6 遇到的问题,参考下列三个 issues: https://github.com/rackt/react-router/issues/1059 https://github.com/rackt/react-router/issues/975 https://github.com/react-bootstrap/react-router-bootstrap/issues/91
在你的 Compontes 后面加这句: YourClass.contextTypes = { router: function() { return React.PropTypes.func.isRequired } } 同时,constructor 这样写: constructor(props, context){ super(props) context.router }
(其实都是因为 ES6 的 Class 不支持直接定义属性。
react-router nest url worked need webpack-dev-server setting: `historyApiFallback: true` , and `/bundle.js` not `bundle.js`
2.8 Webpack
here a article SurviveJS - Webpack Compared Webpack 最大的特点是可以打包一切资源,包括 css, html, 图片等等各种文件基本要素就 3 个:
- entry
- output
- module
2.9 SVG
- 版本解析
目前大多用的是 SVG 1.1,SVG 2.0 还在制作中(https://www.w3.org/TR/SVG2/)。Svg 的 version 属性可以声明版本,类似 html 的 doctype。
- 使用方式
Svg 在 html 文件声明 类型为 application/xhtml+xml 时可以直接插入 html 代码中。还可以用 object,iframe,img(firefox 4.0 版本以下不支持) 标签来嵌入
- 文件格式
Svg 文件一般以 .svg 结尾,压缩版为.svgz
- 网格
 左上角为(0,0),像素为单位用户单位和屏幕单位的映射关系被称为用户坐标系统。除了缩放之外,坐标系统还可以旋转、倾斜、翻转。默认的用户坐标系统 1 用户像素等于设备上的 1 像素(但是设备上可能会自己定义 1 像素到底是多大)。
左上角为(0,0),像素为单位用户单位和屏幕单位的映射关系被称为用户坐标系统。除了缩放之外,坐标系统还可以旋转、倾斜、翻转。默认的用户坐标系统 1 用户像素等于设备上的 1 像素(但是设备上可能会自己定义 1 像素到底是多大)。
- 像素
Svg 中的 1 像素默认是对应输出设备的 1 像素,svg 也能用绝对单位比如 cm,pt,in 等。 Viewbox 属性是改变 svg 的显示区域 http://www.zhangxinxu.com/wordpress/2014/08/svg-viewport-viewbox-preserveaspectratio/
- 基本形状
<?xml version="1.0" standalone="no"?> <svg width="200" height="250" version="1.1" xmlns="http://www.w3.org/2000/svg"> <rect x="10" y="10" width="30" height="30" stroke="black" fill="transparent" stroke-width="5"/> <rect x="60" y="10" rx="10" ry="10" width="30" height="30" stroke="black" fill="transparent" stroke-width="5"/> <circle cx="25" cy="75" r="20" stroke="red" fill="transparent" stroke-width="5"/> <ellipse cx="75" cy="75" rx="20" ry="5" stroke="red" fill="transparent" stroke-width="5"/> <line x1="10" x2="50" y1="110" y2="150" stroke="orange" fill="transparent" stroke-width="5"/> <polyline points="60 110 65 120 70 115 75 130 80 125 85 140 90 135 95 150 100 145" stroke="orange" fill="transparent" stroke-width="5"/> <polygon points="50 160 55 180 70 180 60 190 65 205 50 195 35 205 40 190 30 180 45 180" stroke="green" fill="transparent" stroke-width="5"/> <path d="M20,230 Q40,205 50,230 T90,230" fill="none" stroke="blue" stroke-width="5"/> </svg>
<path> 比较复杂,具体看 https://developer.mozilla.org/zh-CN/docs/Web/SVG/Tutorial/Paths https://www.w3cplus.com/svg/svg-path.html
path 元素的形状是通过属性 d 定义的,属性 d 的值是一个“命令+参数”的序列,我们将讲解这些可用的命令,并且展示一些示例。每一个命令都用一个关键字母来表示,比如,字母“M”表示的是“Move to”命令,当解析器读到这个命令时,它就知道你是打算移动到某个点。跟在命令字母后面的,是你需要移动到的那个点的 x 和 y 轴坐标。比如移动到(10,10)这个点的命令,应该写成“M 10 10”。这一段字符结束后,解析器就会去读下一段命令。每一个命令都有两种表示方式,一种是用大写字母,表示采用绝对定位。另一种是用小写字母,表示采用相对定位(例如:从上一个点开始,向上移动 10px,向左移动 7px)。因为属性 d 采用的是用户坐标系统,所以不需标明单位。在后面的教程中,我们会学到如何让变换路径,以满足更多需求。
- fill 和 stroke
关于填充和边框的属性,包括 fill-rule,用于定义如何给图形重叠的区域上色;stroke-miterlimit,定义什么情况下绘制或不绘制边框连接的 miter 效果;还有 stroke-dashoffset,定义虚线开始的位置
- 坐标系
2.11 cookie & session
cookie 和 session 都用来保存状态
2.11.1 cookie
cookie 是 http 协议的一部分,它的处理分为如下几步:
- 服务器向客户端发送 cookie。
- 通常使用 HTTP 协议规定的 set-cookie 头操作。
- 规范规定 cookie 的格式为 name = value 格式,且必须包含这部分。
- 浏览器将 cookie 保存。
每次请求浏览器都会将 cookie 发向服务器。
其他可选的 cookie 参数会影响将 cookie 发送给服务器端的过程,主要有以下几种:
- path:表示 cookie 影响到的路径,匹配该路径才发送这个 cookie。
- expires 和 maxAge:告诉浏览器这个 cookie 什么时候过期,expires 是 UTC 格式时间,maxAge 是 cookie 多久后过期的相对时间。当不设置这两个选项时,会产生 session cookie,session cookie 是 transient 的,当用户关闭浏览器时,就被清除。一般用来保存 session 的 sessionid。
- secure:当 secure 值为 true 时,cookie 在 HTTP 中是无效,在 HTTPS 中才有效。
- httpOnly:浏览器不允许脚本操作 document.cookie 去更改 cookie。一般情况下都应该设置这个为 true,这样可以避免被 xss 攻击拿到 cookie。
2.11.2 session
cookie 虽然很方便,但是使用 cookie 有一个很大的弊端,cookie 中的所有数据在客户端就可以被修改,数据非常容易被伪造,那么一些重要的数据就不能存放在 cookie 中了,而且如果 cookie 中数据字段太多会影响传输效率。为了解决这些问题,就产生了 session,session 中的数据是保留在服务器端的。
session 的运作通过一个 sessionid 来进行。sessionid 通常是存放在客户端的 cookie 中,比如在 express 中,默认是 connect.sid 这个字段,当请求到来时,服务端检查 cookie 中保存的 sessionid 并通过这个 sessionid 与服务器端的 session data 关联起来,进行数据的保存和修改。
这意思就是说,当你浏览一个网页时,服务端随机产生一个 1024 比特长的字符串,然后存在你 cookie 中的 connect.sid 字段中。当你下次访问时,cookie 会带有这个字符串,然后浏览器就知道你是上次访问过的某某某,然后从服务器的存储中取出上次记录在你身上的数据。由于字符串是随机产生的,而且位数足够多,所以也不担心有人能够伪造。伪造成功的概率很低。
session 可以存放在 1)内存、2)cookie 本身、3)redis 或 memcached 等缓存中,或者 4)数据库中。
2.12 Server
2.14 Security
3 Node
3.1 Koa
koa 和 express 都是基于 connect 的,koa 比 express 稍微轻量一点(其实我觉得差不多),但 koa 最大的两点是 generator。然而随着 ES6 和 ES7 的推出,koa 中这种依靠 generator 的异步方式也渐渐式微,于是推出了 koa2。
koa 和 express 的开发更像是中间件的堆砌
3.2 Loopback
Loopback is based Express.
- using 'z-' prefix to boot scripts ensure that these scripts are run last when the application boots.
4 Android
当年我开发 Android 的时候,还没有统一的设计规范,设备的屏幕也是大小不一很难适配。开发环境还是 Eclipse+Android SDK,看到现在完备的开发工具真是羡慕。
5 Git
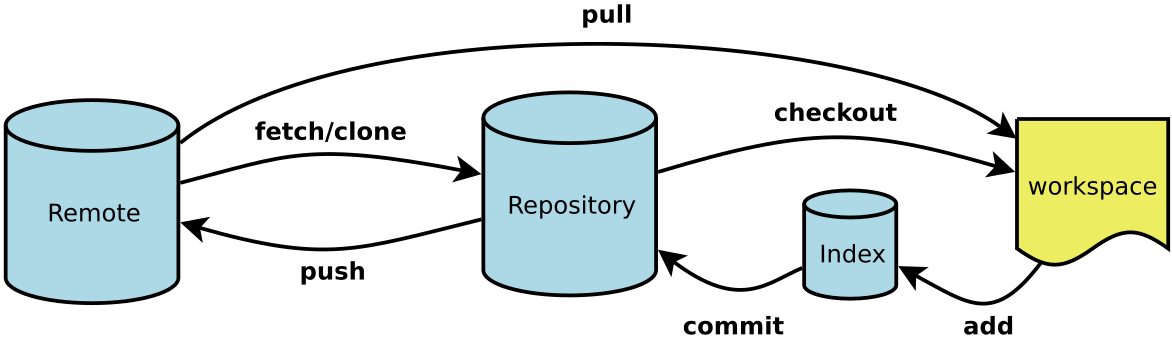
5.1 常用命令
$ git init # 在当前目录新建一个 Git 代码库 $ git clone [url] # 下载一个项目和它的整个代码历史 $ git config --list # 显示当前的 Git 配置 $ git config -e [--global] # 编辑 Git 配置文件 $ git add # 添加指定文件到暂存区 $ git rm # 删除工作区文件,并且将这次删除放入暂存区 $ git commit -m [message] # 提交暂存区到仓库区 $ git commit -a # 提交工作区自上次 commit 之后的变化,直接到仓库区 $ git commit --amend -m [message] # 使用一次新的 commit,替代上一次提交 如果代码没有任何新变化,则用来改写上一次 commit 的提交信息 $ git commit --amend [file1] [file2] ... # 重做上一次 commit,并包括指定文件的新变化 # 分支相关 $ git branch # 列出所有本地分支 $ git branch -r # 列出所有远程分支 $ git branch [branch-name] # 新建一个分支,但依然停留在当前分支 $ git checkout [branch-name] # 切换到指定分支,并更新工作区 $ git checkout -b [branch] # 新建一个分支,并切换到该分支 $ git branch [branch] [commit] # 新建一个分支,指向指定 commit $ git checkout -b [branch] [tag] # 新建一个分支,指向某个 tag $ git branch --track [branch] [remote-branch] # 新建一个分支,与指定的远程分支建立追踪关系 $ git branch --set-upstream [branch] [remote-branch] # 建立追踪关系,在现有分支与指定的远程分支之间 $ git merge [branch] # 合并指定分支到当前分支 $ git cherry-pick [commit] # 选择一个 commit,合并进当前分支 $ git branch -d [branch-name] # 删除分支 $ git push origin --delete [branch-name] # 删除远程分支 $ git branch -dr [remote/branch] # 删除远程分支 # 标签 $ git tag # 列出所有 tag $ git tag [tag] # 新建一个 tag 在当前 commit $ git tag [tag] [commit] # 新建一个 tag 在指定 commit $ git show [tag] # 查看 tag 信息 $ git push [remote] [tag] # 提交指定 tag $ git push [remote] --tags # 提交所有 tag # 查看 $ git status # 显示有变更的文件 $ git log # 显示当前分支的版本历史 $ git log --stat # 显示 commit 历史,以及每次 commit 发生变更的文件 $ git log --follow [file] # 显示某个文件的版本历史,包括文件改名 $ git log -p [file] # 显示指定文件相关的每一次 diff $ git blame [file] # 显示指定文件是什么人在什么时间修改过 $ git diff # 显示暂存区和工作区的差异 $ git diff --cached [file] # 显示暂存区和上一个 commit 的差异 $ git diff HEAD # 显示工作区与当前分支最新 commit 之间的差异 $ git diff [first-branch]...[second-branch] # 显示两次提交之间的差异 $ git show [commit] # 显示某次提交的元数据和内容变化 $ git show --name-only [commit] # 显示某次提交发生变化的文件 $ git show [commit]:[filename] # 显示某次提交时,某个文件的内容 $ git reflog # 显示当前分支的最近几次提交 # 远程 $ git fetch [remote] # 下载远程仓库的所有变动 $ git remote -v # 显示所有远程仓库 $ git remote show [remote] # 显示某个远程仓库的信息 $ git remote add [shortname] [url] # 增加一个新的远程仓库,并命名 $ git pull [remote] [branch] # 取回远程仓库的变化,并与本地分支合并 $ git push [remote] [branch] # 上传本地指定分支到远程仓库 $ git push [remote] --force # 强行推送当前分支到远程仓库,即使有冲突 $ git push [remote] --all # 推送所有分支到远程仓库 # 撤销 $ git checkout [file] # 恢复暂存区的指定文件到工作区 $ git checkout [commit] [file] # 恢复某个 commit 的指定文件到工作区 $ git checkout . # 恢复上一个 commit 的所有文件到工作区 $ git reset [file] # 重置暂存区的指定文件,与上一次 commit 保持一致,但工作区不变 $ git reset --hard # 重置暂存区与工作区,与上一次 commit 保持一致 $ git reset [commit] # 重置当前分支的指针为指定 commit,同时重置暂存区,但工作区不变 $ git reset --hard [commit] # 重置当前分支的 HEAD 为指定 commit,同时重置暂存区和工作区,与指定 commit 一致 $ git reset --keep [commit] # 重置当前 HEAD 为指定 commit,但保持暂存区和工作区不变 $ git revert [commit] # 新建一个 commit,用来撤销指定 commit,后者的所有变化都将被前者抵消,并且应用到当前分支
5.2 Pull-Request steps
The beginner's guide to contributing to a GitHub project
- git clone git@github xxx
- git remote add upstream git@github (original repo)
- git checkout -b newbranch AND do something
- git push origin newbranch(local name):newbranch(remote name)
- git pull –rebase upstream master (sync with origin repo)
5.3 学习资源:
- git - 简明指南 - 助你入门 git 的简明指南,木有高深内容 ;)
- pro git(中文版)
- Git 教程
- Git 参考手册
- Git 指南
- Learn Git Branching
- vimgifs - 通过 Gif 展示 vim 快捷键的效果
6 Text Editor
6.1 Vim
《Practice Vim》是一本非常棒的书,以下几个命令是从中学到的基本技巧:
% 在对应括号跳转 :s/old/new 替换 c change A 直接到行尾 s 修改 * 搜索 . 重复上一条命令 >G 缩进一格 q 记录宏 @ 提取宏
Vim 的宏在进行批量修改时,是神器
一些资源:
- 简明 Vim 练级攻略
- 笨方法学 Vimscript
- What is your most productive shortcut with Vim?
- Vim Awesome - a directory of Vim plugins sourced from GitHub
- vim 推荐配置
6.2 Emacs
6.3 Spacemacs
spacemacs 是一款社区维护的 Emacs 配置,结合了 vim 和 Emacs 两者的优点。
安装 Spacemacs 可以直接 git clone Spacemacs 的 repo 到 Dropbox(或其他云盘)中,然后 ln -s 到 home 目录的 `.emacs.d` 文件夹下。此处可以选择用 master 还是 develop 分支。然后新建 `.spacemacs` 文件夹,在.spacemacs 中的 init.el 为 Spacemacs 的启动配置文件(这个文件可自动生成,用 dotspacemacs/copy-template 命令),其余的配置写进自己的 layer 里。Layer 这个概念和 package 不一样,Spacemacs 基于 layer 来配置。
6.3.1 Use-Package
(use-package foo) :init 加载 package 之前执行的命令 :config 加载 package 之后执行的命令
6.3.2 Tips
If you get an error regarding package downloads then you may try to disable HTTPS protocol by starting Emacs with
emacs --insecure
6.3.3 Shortcuts
C-h f & C-h C-f : Find Function definition C-h v & C-h C-v : Find variable definition SPC s l : Navigation functions in current file SPC f e d : Go to your .spacemacs file SPC f e i : Go to .emacs.d/init.el SPC h L : Find an elpa library SPC f e h : Find Spacemacs layers, docs and package configuration SPC b b & SPC b B(i) : show all opened buffer SPC b h : Open spacemacs home buffer SPC b s : Open scratch buffer SPC b f : Reveal in finder SPC b w : Read only mode. SPC b n/p : previous or next buffer SPC b TAB : to switch back and forth. SPC f f : helm find file SPC f r : open recent file SPC f R : rename file SPC f c : copy file SPC f j : jump to dired SPC f t : open neo tree SPC f o : open in external application SPC p f / SPC p b : open project file or buffer SPC p t : open project neotree SPC l o : custom layout SPC l L/s : load or save layout SPC l l : switch bewteen layout SPC l TAB : quick way to switch SPC l ? : open up the help. SPC p l : switch to project and create a layout
6.3.4 Resources
Elisp 教程:
6.4 Sublime Text
Material Theme 比 Monokai 更好看。。
7 Org Mode
Org mode is for keeping notes, maintaining TODO lists, planning projects, and authoring documents with a fast and effective plain-text system.
- Org Mode - Organize Your Life In Plain Text! – 参考这份文档来配置
7.1 useful package:
7.1.1 org-mac-link
Installation
Customize the org group by typing M-x customize-group RET org RET, then expand the Modules section, and enable mac-link.
You may also optionally bind a key to activate the link grabber menu, like this:
(add-hook 'org-mode-hook (lambda () (define-key org-mode-map (kbd "C-c g") 'org-mac-grab-link)))
7.1.2 Org-IO Slide
8 Chrome
Chrome develop tool 有很多小技巧,之后整理一下
- cVim
- Markdown Here
- One Tab
- 新同文堂 - 繁简转换
9 OS
9.1 Linux
9.1.1 学习链接
9.1.2 实验室服务器搭建
- 修改网络
修改 /etc/network/interfaces
- 用到的命令
uname -r # display your kernel version sudo apt-get update # Update package information sudo apt-get install apt-transport-https ca-certificates # ensure that APT works with the https method, and that CA certificates are installed echo $SHELL show default shell sudo chsh -s $(which zsh) 设置 zsh 为默认 shell sudo passwd 用户名 设置该用户密码
9.2 Mac OS
- Mac OS X Setup Guide
- jaywcjlove/awesome-mac: This repo is a collection of awesome Mac applications and tools for developers and designers.
- Alfred - 替换系统 Spotlight 的免费软件,更美观更强大
- alfredworkflow - 超多的 alfredworkflow
- Dropbox - 文件同步工具
- Chrome - 跨平台可替代 safari
- Homebrew - 软件包管理工具
- homebrew-cask - 使用命令行方式安装软件
- oh-my-zsh - zsh 的安装配置文件
- XtraFinder - 文件管理器
- MplayerX - 强大的视频播放器
- iTerm2 - 第三方终端
- Mou - Markdown 写作工具
- F.liux - 护眼
- Evernote - 个人知识管理
9.3 Windows
- 2014 年软件推荐 - 写的太全了
10 Database
10.1 MySQL
10.1.1 导入 CSV 文件
MySQL 导入 csv 可以用 LOAD DATA
mysql --local-infile -u user -p source <path>/loadcsv.sql LOAD DATA LOCAL INFILE "<file path>" INTO TABLE `<table name>` FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' (<col1, col2, col3...>);
之所以要加 --local-infile ,是因为会报错: ERROR 1148 (42000): The used command is not allowed with this MySQL version
可能原因(from mysql reference manual): If LOAD DATA LOCAL is disabled, either in the server or the client, a client that attempts to issue such a statement receives the following error message: ERROR 1148: The used command is not allowed with this MySQL version 可见,出于安全考虑,默认是不允许从 client host 远程通过 load data 命令导数据的解决办法: For the mysql command-line client, enable LOAD DATA LOCAL by specifying the –local-infile[=1]option, or disable it with the –local-infile=0 option 也即,在需要从 client host 导数据的情况下,登陆 mysql 时,需用–local-infile[=1]显式指定参数,典型命令形式为: mysql –local-infile -u user -ppasswd 登陆成功后,执行 load data infile 'filename' into table xxx.xxx 即可
导入脚本参考 MySQL 官方文档:
10.2 MongoDB
Schema 设计原则:设计数据库 Schema 是在已知数据库系统特性、数据本质以及应用程序需求的情况下为数据集选择最佳表述的过程。
use database 添加用户 db.createUser({user: "username", pwd: "password", roles: []})
10.3 Redis
推荐《Redis 入门指南》一书入门。
Redis 是一个开源、高性能、基于键值对的缓存与存储系统,通过提供多种键值数据类型来适应不同场景下的缓存与存储需求。
10.3.1 数据类型
不论何种数据类型,它的字段值都只能为字符串类型。
- 字符串类型
一般实践以=对象类型.对象 ID.对象属性=命名
- 散列类型
适合存储的对象:使用对象类别和 ID 构成键名,使用字段表示对象的属性,而字段值则存储属性值
- 列表类型
可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。
列表类型内部是使用双向链表(double linked list)实现的,所以向两端添加元素很快,时间复杂度为 O(1)。但通过索引来访问元素比较慢。
所以适合获取最新内容或两端插入内容的场景
- 集合类型
最常用的操作是向集合中加入或删除元素,判断是否存在等。可以方便的和多个集合间进行并集、交集、差集的计算。
- 有序集合类型
比集合类型多了一个「分数」,所以有序。
- 有序集合是使用散列表和跳跃表实现的,所以读取位于中间部分的数据也很快,时间复杂度是 O(log(N))
- 可通过调整「分数」来调整元素的位置
- 比列表类型更耗内存
10.4 PostgreSQL
11 Algorithm
11.1 经典论文
11.2 图
11.2.1 定义
图是由顶点的有穷非空集合和顶点之间边的集合组成,通过表示为 G(V,E),其中,G 标示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。
- 无向图 / 有向图
- 稀疏图 / 稠密图
- 完全图 / 有向完全图
- 度 / 入度 / 出度
- 连通图 / 强连通图
连通分量 / 强连通分量

11.2.2 存储结构
常用邻接矩阵


11.2.3 遍历


11.2.5 拓扑排序
11.2.6 关键路径
11.2.7 最短路径
11.3 k-Nearest Neighbors algorithm
俗话说:“物以类聚,人以群分”,亦或“近朱者赤,近墨者黑”。k-Nearest Neighbors algorithm(k-邻近法,以下简称 kNN) 就是利用了这样一种思想发展起来的分类算法。kNN 算法是最简单的机器学习/模式识别算法之一。
11.3.1 定义
我自己是这么理解的:通过找最近邻居的方法,来判定自己到底是哪一类人
具体来说:

如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示现在需要给这个绿色的圆分类。
- 要判别上图中那个绿色的圆是属于哪一类数据,需从它的邻居下手。但一次性看多少个邻居呢?k 值即一次找多少个邻居。从上图中,你还能看到:
- 如果 K=3,绿色圆点的最近的 3 个邻居是 2 个红色小三角形和 1 个蓝色小正方形,红色占 2/3,所以判定绿色的这个待分类点属于红色的三角形一类。
- 如果 K=5,绿色圆点的最近的 5 个邻居是 2 个红色三角形和 3 个蓝色的正方形,蓝色占 3/5,判定绿色的这个待分类点属于蓝色的正方形一类。
11.3.2 特点
- Lazy Learning Algorithm:接到测试样例才会进行 kNN 算法计算,并且会搜索所有的样本数据,最终给出直接分类,没有其它的信息可用。
- Non-parameter:直接计算,基于实例(Instance Based),
- Majority Vote:邻近节点的属于某类别的多数决定。
11.3.3 关键因素
- 数据集合
数据的所有特征都要做可比较的量化
因为以下等原因:
- 我们度量各个特征的时候度量单位不同
- 非数值数据如何度量
- 数据权重如何确定
- 距离(或相似性)计算
K 近邻算法的核心在于找到实例点的邻居,这个时候,问题就接踵而至了,如何找到邻居,邻居的判定标准是什么,用什么来度量。
常见的方法:
- 欧氏距离
- 曼哈顿距离
- k 值的选取
- 如果选择较小的 K 值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K 值的减小就意味着整体模型变得复杂,容易发生过拟合;
如果选择较大的 K 值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且 K 值的增大就意味着整体的模型变得简单。
想想 k=1 和 k=N 时的样子
- 分类的方法
一般用的是投票法(多数表决)
11.3.4 算法步骤
- 准备数据,对数据进行预处理
- 选用合适的数据结构存储训练数据和测试元组
- 计算已知类别数据集中每个点与当前点的距离;
- 选取与当前点距离最小的 K 个点;
- 统计前 K 个点中每个类别的样本的相似性;
- 返回前 K 个点中相似性最高的类别作为当前点的预测分类。
11.3.5 具体实现
- 线性扫描
其实就是把数据集中所有数据遍历一遍计算
- k-d 树
kNN 的本质是对特征空间的划分,kd 树的思想就是用线段树来表示这种划分,使得搜索效率提高为 O(mlog(n))
k-d 树是每个节点都为 k 维点的二叉树。所有非叶子节点可以视作用一个超平面把空间分割成两个半空间( Half-space )。节点左边的子树代表在超平面左边的点,节点右边的子树代表在超平面右边的点。选择超平面的方法如下:每个节点都与 k 维中垂直于超平面的那一维有关。因此,如果选择按照 x 轴划分,所有 x 值小于指定值的节点都会出现在左子树,所有 x 值大于指定值的节点都会出现在右子树。这样,超平面可以用该 x 值来确定,其法矢为 x 轴的单位向量。
下图为直观的 k-d 树对特征空间的划分。

12 Design
12.1 Sketch
- Sketch 中文网
Keyboard Shortcuts for Sketch App
「共享样式」和「符号」功能很棒
12.2 贝塞尔曲线
Bézier curve(贝塞尔曲线)是应用于二维图形应用程序的数学曲线。曲线定义:起始点、终止点(也称锚点)、控制点。通过调整控制点,贝塞尔曲线的形状会发生变化。1962 年,法国数学家 Pierre Bézier 第一个研究了这种矢量绘制曲线的方法,并给出了详细的计算公式,因此按照这样的公式绘制出来的曲线就用他的姓氏来命名,称为贝塞尔曲线。
参考:贝塞尔曲线 总结 - PlayBoy's 部落格 - 博客频道 - CSDN.NET
Cubic Bezier Curves - Under the Hood on Vimeo 这个视频则更好的诠释了它的原理:点从 0%到 100%的过程
cubic-bezier(.17,.67,.83,.67) ✿ cubic-bezier.com 这个网站是用来计算动画中用到的贝塞尔曲线数值的。
13 Research
13.1 研究者的任务
- 探索和构思新的想法
- 将想法付诸实验,检验其是否具有可行性
- 将任务 1、2 中得到的研究结果撰写成文稿或者论文,提交给期刊、会议、图书或其他媒介
- 评审来自其他研究者的论文或文稿
- 管理学术起开的运转,组织学术会议
- 参加学术会议,向大会报告论文,学习最新的研究成果,与其他研究者进行讨论,交换想法
- 向政府或其他机构申请研究经费,用来支持科研工作的开展和研究生的培养
- 指导研究生尤其是博士生的研究,以便他们能在不久的将来成为独立的研究者
- 教授研究生和本科生课程
- 为所属院系部门和机构做些行政工作
- 技术转让或创业
13.2 研究者类型
- 学术和基础性研究类型
- 实验性研究类型
- 应用方向和创业类型
13.3 博士目标
- 成为最好
- 成为独立的研究者
13.4 一个好的研究问题应具备以下几个条件:
- 明显的益处
- 描述简单
- 尚不具有明确的解法
- 解决方案具备可测试性,大问题可以拆分成若干个子问题,能观察到每个子问题的进程
13.5 Paper
13.5.1 如何阅读论文
When reading a research paper, the following is the essential information that is focused on and written down:
- The Concept: What, conceptually, are the authors trying to achieve? What is the goal of the work? This can also be reformulated as:What is the contribution of the paper? (What’s new here?)
- The Implementation: How is the concept realized? How do the authors support their hypothesis? How do they implement the concept?
- Related Work: What previous work does this paper build upon? Almost all research papers build heavily upon the work of one or two previous papers.What are these?
- other.e.g,visualization: Data Characteristics:What are the characteristics of the data analyzed and visualized in the paper? What is the spatial dimensionality? (2D, surfaces, or 3D) What is the temporal dimensionality? (static or time-dependent) What is the resolution and size of the data set? Is the dataset multi-resolution or adaptive resolution? Are the data samples given on a structured or unstructured grid? Is it scalar, vector, or tensor data? Is itmulti-variate data?
- 阅读顺序:
先看 Abstract 和 Introduction,重点看 Abstract,学会只看 Abstract 和 Introduction 便可以判断出这篇论文的重点和你的研究有没有直接关连,从而决定要不要把它给读完。看完 Introduction 要搞清楚三个问题:
- 在这领域内最常被引述的方法有哪些?
- 这些方法可以分成哪些主要派别?
- 每个派别的主要特色(含优点和缺点)是什么?
接着读论文主体,要弄懂三个问题:
- 这篇论文的主要假设是什么(在什么条件下它是有效的),并且评估一下这些假设在现实条件下有多容易(或多难)成立。愈难成立的假设,愈不好用,参考价值也愈低。
- 在这些假设下,这篇论文主要有什么好处。
这些好处主要表现在哪些公式的哪些项目的简化上。至于整篇论文详细的推导过程,你不需要懂。除了三、五个关键的公式(最后在应用上要使用的公式, 你可以从这里评估出这个方法使用上的方便程度或计算效率,以及在非理想情境下这些公式使用起来的可靠度或稳定性)之外,其它公式都不懂也没关系,公式之间的恒等式推导过程可以完全略过去。假如你要看公式,重点是看公式推导过程中引入的假设条件,而不是恒等式的转换。
但是,在你开始根据前述问题念论文之前,你应该先把这派别所有的论文都拿出来,逐篇粗略地浏览过去(不要勉强自己每篇或每行都弄到懂,而是轻松地读,能懂就懂,不懂就不懂),从中挑出容易念懂的 papers,以及经常被引述的论文。然后把这些论文照时间先后次序依序念下去。
- 补充:
- 不要逐行阅读。
- 敢于想象(猜),猜完验证。
- 大规模,分批次阅读,不要逐篇阅读(这篇读不懂的,可能在另一篇中有答案)。
- 硕士生应该学会选择性的阅读,提炼出适合自己的阅读论文顺序,大量阅读提升广度,精准阅读提升深度。
- 为什么要坚持培养阅读与分析期刊论文的能力
只要深入掌握到阅读与分析期刊论文的技巧, 就可以掌握到大学生不曾研习过的三种能力:
- 自己从无组织的知识中检索、筛选、组织知识的能力
- 对一切既有进行精确批判的独立自主判断能力
- 创造新知识的能力
- 参考文献:
- Laramee, R. S. (2011). How to read a visualization research paper: Extracting the essentials. IEEE Computer Graphics and Applications, 31(3), 78–82. http://doi.org/10.1109/MCG.2011.44
- 彭明辉 研究所新生完全求生手册
13.6 Math
14 Visualization
14.2 Video Visualization
A video visualization pipeline is a data flow pipeline, consisting of a series of functional components, namely video capture ⇒ data communication⇒data management⇒video processing⇒video visualization.
15 Machine Learning
16 Computer Graphics
16.1 图形学概念
16.2 Confrence & Paper
16.4 WebGL

17 Complex Network
17.1 2016 第十二届中国网络科学论坛
17.1.1 用散度理论观察网络(李幼平院士)
用场论来思考网络建模,在关注边的时候,不要忽略点双结构 Web 网络结构从最初的相互连接(泊松分布)到后来的大规模网络单向输出(幂率分布)
17.2 Link Prediction
17.2.1 概念
- 网络
描述某物与某物之间联系的一种方式。一般由点和边构成。
- 如何刻画网络
图论
- 两个节点间的距离
连接这两个节点的最短路径所包含的边的数目
- 平均距离
公式 1
- 度
- 无向图中:与节点相连的边的数目
有向图中:出度是从该节点指向其他节点的边的数目,入度与出度相反。
平均度:网络中所有节点的度的平均值度分布:网络中度为 k 的节点数占节点总数的比例
- 小世界效应
如果网络的平均度固定,平均距离随网络节点数以对数的速度或者慢于对数的速度增长
- 无标度特性
很多真实网络的分布,都近似的遵从幂函数的形式
- 局部结构
- 节点与链路的中心性
度中心性:节点的度
- 一般而言,一个节点的度越大,则这个节点越重要
- 节点的传播影响力与其所处的网络的位置有关
节点的重要性与其网络的结构和功能有关
介数:用于衡量某节点在基于最短路径的路由策略下信息的吞吐量介数中心性:网络中节点对最短路径中经过该节点的数目占所有最短路径数的比例接近中心性:节点与网络中其他节点最短距离的平均值
其他还有:
- 特征向量中心性
- 路由中心性
- 子图中心性
- 环中心性
- 群落结构
群落内部连边密集,群落之间连边很少
- 关联性
一条边所连接的两个节点度之间的关联
- 正相关:度大的节点倾向于和度小的节点相连
- 负相关:度大的节点倾向于和度小的节点相连
- 熵
17.2.2 图的类型
- 加权有向图
- 加权无向图
- 无权有向图
- 无权无向图(简单图)
17.2.4 链路预测的基本方法
17.2.5 Networkx
18 Latex
www.mohu.org/info/lshort-cn.pdf attach3.bdwm.net/attach/boards/MathTools/M.1364651898.A/texintrotalk.pdf math.nju.edu.cn/~meijq/tex/lnotes.pdf
\setmainfont{Times New Roman}%缺省英文字体.serif 是有衬线字体 sans serif 无衬线字体 \setCJKmainfont[ItalicFont={Kai}, BoldFont={Hei}]{STSong}%衬线字体 缺省中文字体为 \setCJKsansfont{STSong} \setCJKmonofont{STFangsong}%中文等宽字体 %-----------------------xeCJK 下设置中文字体------------------------------% \setCJKfamilyfont{song}{SimSun} %宋体 song \newcommand{\song}{\CJKfamily{song}} \setCJKfamilyfont{fs}{FangSong_GB2312} %仿宋 2312 fs \newcommand{\fs}{\CJKfamily{fs}} \setCJKfamilyfont{yh}{Microsoft YaHei} %微软雅黑 yh \newcommand{\yh}{\CJKfamily{yh}} \setCJKfamilyfont{hei}{SimHei} %黑体 hei \newcommand{\hei}{\CJKfamily{hei}} \setCJKfamilyfont{hwxh}{STXihei} %华文细黑 hwxh \newcommand{\hwxh}{\CJKfamily{hwxh}} \setCJKfamilyfont{asong}{Adobe Song Std} %Adobe 宋体 asong \newcommand{\asong}{\CJKfamily{asong}} \setCJKfamilyfont{ahei}{Adobe Heiti Std} %Adobe 黑体 ahei \newcommand{\ahei}{\CJKfamily{ahei}} \setCJKfamilyfont{akai}{Adobe Kaiti Std} %Adobe 楷体 akai \newcommand{\akai}{\CJKfamily{akai}} %------------------------------设置字体大小------------------------% \newcommand{\chuhao}{\fontsize{42pt}{\baselineskip}\selectfont} %初号 \newcommand{\xiaochuhao}{\fontsize{36pt}{\baselineskip}\selectfont} %小初号 \newcommand{\yihao}{\fontsize{28pt}{\baselineskip}\selectfont} %一号 \newcommand{\erhao}{\fontsize{21pt}{\baselineskip}\selectfont} %二号 \newcommand{\xiaoerhao}{\fontsize{18pt}{\baselineskip}\selectfont} %小二号 \newcommand{\sanhao}{\fontsize{15.75pt}{\baselineskip}\selectfont} %三号 \newcommand{\sihao}{\fontsize{14pt}{\baselineskip}\selectfont} %四号 \newcommand{\xiaosihao}{\fontsize{12pt}{\baselineskip}\selectfont} %小四号 \newcommand{\wuhao}{\fontsize{10.5pt}{\baselineskip}\selectfont} %五号 \newcommand{\xiaowuhao}{\fontsize{9pt}{\baselineskip}\selectfont} %小五号 \newcommand{\liuhao}{\fontsize{7.875pt}{\baselineskip}\selectfont} %六号 \newcommand{\qihao}{\fontsize{5.25pt}{\baselineskip}\selectfont} %七号
19 日本语学习
日语由两部分构成:假名、真名(汉字)假名又有两部分构成:平假名、片假名
平假名是由汉字草书简化演变而来,平时用的最多片假名的发音和平假名一一对应,由汉字楷体偏旁演化而来,但是字形相对简单,主要用于:外来语、动植物、拟声词
还有一类:罗马字,即用英文表达日语发音
学习书目:
- 《别笑,我是日语学习书》
- 《我的第一本日语学习书》
20 Life
20.1 Finance
20.2 Fitness
一般而言,让肌肉最大化的发展方式是,使用单次能举起的最大重量的 75%进行训练。对于多数人,使用这种重量,可以针对上半身做 8-12 次反复动作,针对腿部做 12-15 次反复动作。你能举起的重量取决于三个因素:
- 你能征用的肌纤维的数量
- 单根纤维的强度
你所使用的技巧
两种基本耐力:
- 肌肉耐力
- 心肺耐力
20.3 Music Theory
20.5 Blues Harmonica
20.6 Music
由于版权的问题,国内的软件现在很多曲库都不太全了 iTunes 还不错,唯一缺点是通过 iCloud 同步 My Music 较慢
20.7 Podcast
IT 类:
- 内核恐慌
- IT 公论
teahour.FM
其余的:
- 聆听古典
20.8 Download Resources
20.9 科学上网
20.9.1 VPS + docker + shadowsocks 自建工具
Docker + DigitalOcean + Shadowsocks 5 分钟科学上网 // Jin Liu
docker pull oddrationale/docker-shadowsocks docker run -d -p 1984:1984 oddrationale/docker-shadowsocks -s 0.0.0.0 -p 1984 -k paaassswwword -m aes-256-cfb 上述命令中的 paaassswwword 就是配置客户端需要的密码,你可以换成你自己的密码,1984 是端口。
20.10 Job
- Github 简历生成
- 简历生成
- 简历大厨
- Resume template for Chinese programmers
- 最好用的 MarkDown 在线简历工具 - 可在线预览、编辑、设置访问密码和生成 PDF
20.11 创业
20.11.1 期权
期权在授予时是不需要你掏钱的,在行权时也是不需要掏钱的
- 期权的计算方法
1、经常听到创业公司的朋友跟我说,老板给了 20 万的期权,老板给了 50 万的期权。我就问他,是价值 20 万美元的期权,还是 20 万股的期权?占公司股本多少?很少有人能就此说清楚。
2、我们通过一个小案例来解读这中间的概念。某 B 轮公司当前估值 1 亿美金,分成了 1 亿股,每股价值 1 美金。公司的期权池占总股本的 15%,也就是 1500 万股期权,每股期权的价值也是 1 美金。公司确定的 B 轮行权价是 5 毛美金。(随着融资轮次的增加,公司的估值会上升,行权价也会上升,C 轮的行权价可能就变成 1.5 美元了)按照市场正常估价,公司希望在 C 轮能达到 3 亿美金的估值。如果上市,参照同类公司,预期市值在 15 亿美金。(大家一定要看清这些数字的关系)
3、那我们来看看所谓的 20 万期权会有多少种解读。第一种叫 20 万股期权,那么是多少股就是多少股,歧义最小;第二种叫价值 20 万美元的期权,这里歧义就大了,这可以是 B 轮估价 20 万美元的期权,那么就是 20 万股,和第一种一样。也可以是 C 轮估价 20 万美元的期权,那么就是 6.7 万股。还可以是上市之后价值 20 万美元的期权,那可就惨了,你其实被授予的期权只有区区的 1.3 万股。
4、上述的股数也好,估值也好,行权价也好,是大家最容易被忽悠的地方。其实最简单的期权价值衡量,你只需要知道公司当前估值多少,你的期权占股份比例就可以了,两下一乘,就是你期权的当前价值。未来价值就看看上市预期市值多少,中间稀释的比例如何,你也可以大致知道如果公司上市,你能收益多少。用上面的案例说明,你被授予 20 万股期权,占公司总股本的 0.2%,当前价值 20 万美元。若干年后上市,公司市值 15 亿美金,在融资过程中你的 0.2%被稀释了 3 倍,变成了 0.067%,那么上市之后的期权价值就是 100 万美元,减去你的行权成本 10 万,实际收益就是 90 万美元。当然还要很悲催地被扣掉不少税。
- 期权的变现方式
- 变现路径一:当然是上市啦,通常变现的倍数最高,为什么?原因其实很简单,收购和投资人回购都是属于股票一级市场行为,因为是相对封闭操作,竞标者少,价钱自然不会喊的很高。而上市则属于股票二级市场行为了,你手中的期权是放在了公开市场中竞购,想买的人多了,自然价格就高了。
- 变现路径二:被收购,通常你的期权也可以变现。当然这里也有几种不同的情况,被现金收购,差不多是可以直接变现的,被上市公司通过换股收购,你的期权变成上市公司的股票或者期权,基本也可以套现,如果是被未上市公司换股收购,那么就还有点曲折,你得等到那家公司的股票可以变现或自由买卖的时候才能变成钱了。
- 变现路径三:这种不太常见,所以知道的人不多,那就是公司在进行某一轮融资的时候,和投资人商量,投资人愿意支付一部分现金来收购公司现有的期权。通常投资人愿意这么做,一种可能是公司发展的很不错,为了对早期团队进行激励,回购部分期权;另一种可能是股权结构上的安排,某个投资人希望增大对于公司的持股比例,也会回购。但总之,被回购期权的持有人是套现了。上述套现即使发生,通常也是在公司的至少 C 轮以后的融资行为中,一般套现的比例比较小,覆盖范围是公司高管或是早期员工,因此不是期权变现的主要途径。
- 注意事项
- 你到底拿了多少期权
- 中途退出就拿不到的期权?
- 是口头承诺,还是书面确认?
能不能变现,怎么变现
20.13 在线编辑器
- Cmd Makrdown
- StackEdit
- notepad.cc - 特别好用
- Office Online
- Slides - 制作在线 PPT
- 马克飞象 - 一款专为印象笔记打造的 Markdown 编辑器
20.14 壁纸
20.15 其他
v2ex 的自定义 CSS: @import url("//dn-startplay.qbox.me/v2ex-material-theme2/v2ex.min.css"); @import url("//jkjoke.b0.upaiyun.com/css/v2ex.css");
21 Reading
阅读工具:
Kindle 的墨水屏确实很舒服,但感觉没 iPad Mini 看书爽,尤其是 PDF。我一直用=多看阅读=来看书,因为在上面买了很多书,而且可以用 Evernote 同步笔记。
21.2 Paper
- Paper we love – Papers from the computer science community to read and discuss.